8. その他の機能
2006.03.30 株式会社四次元データ 鈴木 圭
- 8.1. Pluggable Annotation Processing API
- 8.2. Compiler API
- 8.3. ネットワーク・パラメータの取得
- 8.4. CookieManager
- 8.5. 軽量 HTTP サーバ
- 8.6. セキュリティの改善
- 8.7. File クラスの拡張 - ディスク領域/アクセス権限
- 8.8. コンソールでのパスワード入力を隠す
- 8.9. Deque
- 8.10. NavigableSet/NavigableMap
- 8.11. 配列の縮小コピー/拡大コピー/スライス
- 8.12. コア・ライブラリ その他の改善
Mustang のその他の機能ということで、他の項目に分類しなかった機能の解説を行います。アノテーション処理のための Pluggable Annotation Processing API や、Java プログラムから Java ソースコードのコンパイルを可能とする Compiler API のほかに、コア・ライブラリの変更点などを解説します。
8.1. Pluggable Annotation Processing API
J2SE 5.0 "Tiger" で追加されたアノテーション機能を利用すると、プログラムにメタ情報を埋め込むことができます。Tiger の登場以降、アノテーションは多くのライブラリで利用され、開発者はその恩恵を受けてきました。しかし、Tiger ではアノテーションを処理するプログラムの作成にやや煩雑さがあり、さらに tools.jar に含まれる com.sun.mirror 以下のパッケージに含まれるクラスを使用しなければならず、標準機能の中でアノテーションを処理するプログラムを記述することができませんでした。一方、Mustang では Pluggable Annotation Processing API(JSR 269)が導入され、アノテーション処理に関する機能が標準 API としてサポートされています。また、apt(Annotation Processing Tool)の代わりに javac コマンドでもアノテーション処理を行うことができるようになりました(javac コマンドに -processor オプションが追加されています)。
アノテーション処理に関する機能は以下のパッケージで提供されています:
- javax.annotation.processing - アノテーション処理のための機能
- javax.lang.model - Java 言語の要素を表すインタフェースなど
- javax.lang.model.element - 要素を表すインタフェースなど
- javax.lang.model.type - 型を表すインタフェースなど
- javax.lang.model.util - アノテーション処理を補助するユーティリティ
javax.annotation.processing パッケージではアノテーション処理を行うための機能が提供されています。アノテーション・プロセッサを表す Processor インタフェースや、それの実装をサポートする AbstractProcessor 抽象クラスなどが含まれています。また、javax.annotation.model.element パッケージでは Java 言語の構成要素(パッケージやクラス、インタフェースなど)をモデル化するインタフェースなどが定義されています。javax.annotation.model.type パッケージでは配列型(ArrayType)やプリミティブ型(PrimitiveType)、実行可能型(ExecutableType)などの型を表すインタフェースなどが含まれています。アノテーション・プロセッサを作成するための主なインタフェースやアノテーションを以下に示します:
- javax.annotation.processing.Processor
- アノテーション・プロセッサを表すインタフェース。 - javax.annotation.processing.AbstractProcessor
- アノテーション・プロセッサの実装を補助する抽象クラス。通常は AbstractProcessor を継承し、process メソッドをオーバーライドすることでアノテーション・プロセッサを作成します。protected フィールド processingEnv に ProcessingEnvironment を持ちます。 - javax.annotation.processing.ProcessingEnvironment
- アノテーションの処理環境を表すインタフェース。アノテーション・プロセッサに渡されたオプションを返す getOptions メソッドや、ログ出力のための Messager を返す getMessager メソッドなどを持ちます。 - javax.annotation.processing.RoundEnvironment
- アノテーション処理に関する情報を提供するインタフェース。指定したアノテーションに修飾された要素を返す getElementsAnnotatedWith メソッドなどを持ちます。 - javax.annotation.processing.Messager
- メッセージ出力のための printMessage メソッドを提供するインタフェース。 - javax.annotation.processing.SupportedAnnotationTypes
- アノテーション・プロセッサがサポートするアノテーション型を指定するためのアノテーション。 - javax.annotation.processing.SupportedSourceVersion
- アノテーション・プロセッサがサポートする Java のバージョンを指定するためのアノテーション。 - javax.annotation.model.element.Element
- Java 言語の構成要素(パッケージやクラス、メソッドなど)を表すインタフェース。 - javax.lang.model.element.TypeElement
- Java 言語の構成要素のうちクラスやインタフェースを表す Element のサブインタフェース。
カスタム・アノテーション及びアノテーション・プロセッサの作成
それではサンプルとしてカスタム・アノテーション及びそれを処理するアノテーション・プロセッサを作成してみます。作成するカスタム・アノテーションは回文(最初から読んでも最後から読んでも同じ文)を記述するための Palindrome アノテーションとします。Palindrome アノテーションには文字列(回文)を一つだけ指定することができます。そして、Palindrome アノテーションで指定された文字列が実際に回文になっているかどうかをチェックするアノテーション・プロセッサ PalindromeProcessor を作成します。また、作成するものは com.example パッケージに配置することにします。
カスタム・アノテーション Palindrome の定義は以下のようになります:
// Palindrome.java
package com.example;
public @interface Palindrome
{
String value();
}
アノテーションを定義する方法は Tiger の時と同じく @interface を使用します。次にアノテーション・プロセッサ PalindromeProcessor を作成します。アノテーション・プロセッサの一般的な作成手順は以下のようになります:
- AbstractProcessor を継承したクラス(PalindromeProcessor)を作成する。
- SupportedSourceVersion アノテーションでサポートする Java のバージョンを指定する。
- SupportedAnnotationTypes アノテーションでサポートするアノテーション型を指定する。
- process メソッドをオーバーライドし、必要な処理を記述する。
以下に PalindromeProcessor の実装を示します:
// PalindromeProcessor.java
package com.example;
import java.util.Set;
import javax.annotation.processing.AbstractProcessor;
import javax.annotation.processing.Messager;
import javax.annotation.processing.RoundEnvironment;
import javax.annotation.processing.SupportedAnnotationTypes;
import javax.annotation.processing.SupportedSourceVersion;
import javax.lang.model.SourceVersion;
import javax.lang.model.element.Element;
import javax.lang.model.element.TypeElement;
import javax.tools.Diagnostic;
@SupportedSourceVersion(SourceVersion.RELEASE_6)
@SupportedAnnotationTypes("com.example.Palindrome")
public class PalindromeProcessor extends AbstractProcessor
{
@Override
public boolean process(
Set<? extends TypeElement> annotations, RoundEnvironment roundEnv)
{
// (1) 処理対象のアノテーション型についてループ
for(TypeElement annotation : annotations) {
// (2) アノテーション付加されている要素についてループ
for(Element element : roundEnv.getElementsAnnotatedWith(annotation)) {
// (3) 要素に付加されているアノテーションを得る
Palindrome palindrome = element.getAnnotation(Palindrome.class);
// (4) Palindrome アノテーションの値が回文になっているか判定
if(!isPalindrome(palindrome.value())) {
// (5) 警告メッセージを出力
// processingEnv は AbstractProcessor の protected フィールド
Messager messager = processingEnv.getMessager();
String message = String.format("「%s」は回文ではありません", palindrome.value());
messager.printMessage(Diagnostic.Kind.WARNING, message, element);
}
}
}
return true;
}
// 指定された文字列が回文であることを判定する.
private boolean isPalindrome(String string)
{
int left = 0;
int right = string.length() - 1;
while(left < right) {
if(string.charAt(left++) != string.charAt(right--)) {
return false;
}
}
return true;
}
}
今回はサポートする Java のバージョンは 6、アノテーション型は先ほど定義した Palindrome とするため、SupportedSourceVersion アノテーションには SourceVersion.RELEASE_6、SupportedAnnotationTypes アノテーションには "com.example.PalindromeProcessor" を指定しています。SupportedAnnotationTypes には "com.example.*" のようにワイルドカードを用いて指定することもできます。
アノテーションの処理を行う process メソッドのシグネチャは以下の通りです:
boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv)
第一引数の annotations には、処理対象のアノテーション(SupportedAnnotationTypes で指定したアノテーション)に対応する TypeElement の Set が渡されます。第二引数の roundEnv はアノテーション処理に必要な情報を提供する RoundEnvironment です。process メソッドの戻り値は、後続のアノテーション・プロセッサにも処理を行わせたい場合は false、そうでない場合は true とします。
process メソッドの中では、(1)処理対象のアノテーション型一つ一つに対して、(2)そのアノテーションが付加されている要素一つ一つに対して、(3)そのアノテーションを取得し、(4)その値が回文になっているかどうか判定し、(5)回文になっていない場合は警告メッセージを出力する、という処理を行っています((1)〜(5)はプログラム中のコメントに対応します)。(5) の部分のようにメッセージ出力を行う場合は、System.out などに直接出力するのではなく Messager インタフェースの printMessage メソッドによって行います。メッセージの種類は列挙型 javax.tools.Diagnostic.Kind によって指定します。
カスタム・アノテーションの使用と処理
それでは作成した PalindomeProcessor を実際に使用してみます。そのために、Palindrome アノテーションを使用した以下のようなクラスを作成しました:
// PalindromeCollection.java
package com.example;
public class PalindromeCollection
{
@Palindrome("level")
private void palindrome1() { }
@Palindrome("しんぶんし")
private void palindrome2() { }
@Palindrome("もももすももも")
private void palindrome3() { }
@Palindrome("GMailで爺めーる")
private void palindrome4() { }
@Palindrome("よわいわよ マカオのオカマ よわいわよ")
private void palindrome5() { }
}
プログラムとして特に意味のあるものではありませんが、各メソッドに Palindrome アノテーションを付加しています。また、PalindromeProcessor が正しく動作することを確認するために、palindrome4 メソッドの Palindrome アノテーションには回文になっていない文字列を指定しています。
それではこれを PalindromeProcessor によって処理します。アノテーション・プロセッサは apt ではなく javac コマンドに -processor オプションを指定することで行います。-processor オプションには実行するアノテーション・プロセッサの完全限定名を指定します。複数のアノテーション・プロセッサを指定する場合はカンマ(「,」)で区切って指定します。今回は PalindromeProcessor だけを実行したいので、以下のように javac コマンドを実行します:
>javac -processor com.example.PalindromeProcessor com/example/PalindromeCollection.java
実行結果として以下の出力が得られます:
com\example\PalindromeCollection.java:15: 警告:「GMailで爺めーる」は回文ではありません
private void palindrome4() { }
^
8.2. Compiler API
Mustang では Compiler API(JSR 199)が追加され、Java プログラムからソース・ファイルのコンパイルを行えるようになりました。Compilre API のクラスなどは javax.tools パッケージに配置されています。以下に Java ファイルのコンパイルに関係する主なクラス/インタフェースを示します:
- ToolProvider クラス
- JavaCompiler などの実装を得るための static メソッドなどを提供します。 - JavaCompiler インタフェース
- Java コンパイラを表すインタフェースです。 - JavaCompiler.CompilationTask インタフェース
- Java コンパイラによるコンパイル・タスクを表すインタフェースです。 - JavaFileObject インタフェース
- ソース・ファイルやクラス・ファイルなど、ツールの扱うファイルを表すインタフェースです。 - FileManager インタフェース
- ソース・ファイルやクラス・ファイルを扱うマネージャを表すインタフェースです。 - StandardFileManager クラス
- java.io.File ベースのファイルを扱う FileManager です。 - Diagnostic インタフェース
- DiagnosticListener に通知される診断を表すインタフェースです。 - DiagnosticListener インタフェース
- コンパイル時の警告などの通知を受けるためのインタフェースです。
以下に Compiler API を使用して Java ファイルをコンパイルするサンプル・コードを示します:
import java.io.File;
import java.util.Arrays;
import javax.tools.JavaCompiler;
import javax.tools.StandardJavaFileManager;
import javax.tools.ToolProvider;
import javax.tools.JavaCompiler.CompilationTask;
public class CompilerMain
{
public static void main(String[] arguments) throws Exception
{
// (1) JavaCompiler インスタンスを取得.
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
if(compiler == null) {
System.out.println("Compiler is not provided.");
return;
}
// (2) java.io.File ベースのファイル・マネージャ.
StandardJavaFileManager fileManager =
compiler.getStandardFileManager(null, null, null);
// (3) コンパイルするソース・ファイル.
File[] sourceFiles = { new File("resources/Hoge.java"),
new File("resources/Piyo.java") };
// (4) コンパイル・オプション.
String[] options = { "-verbose", "-g:none" };
// (5) コンパイル・タスクを取得する.
CompilationTask task = compiler.getTask(
null, fileManager, null, Arrays.asList(options),
null, fileManager.getJavaFileObjects(sourceFiles));
// (6) コンパイル・タスクを実行し, 結果を表示する.
boolean result = task.call();
System.out.println(result);
}
}
ソース・コード中の (1) の部分ではプラットフォームで提供されている JavaCompiler インスタンスを取得するために ToolProvider クラスの getSystemJavaCompiler メソッドを使用しています。JavaCompiler の実装は拡張機能機構を利用して提供することができます。拡張機能機構とはオプション・パッケージなどを提供するための機構で、Java 拡張ディレクトリ(JDK_HOME/jre/lib/ext または JRE_HOME/lib/ext)に必要な JAR ファイルを配置することで対象のパッケージをアプリケーションで利用可能とすることができます。JDK に付属しているコンパイラを使用する場合は、JDK_HOME/lib/tools.jar を Java 拡張ディレクトリにコピーしておくことで利用可能となります(tools.jar をクラス・パスに含めておくことでも可能です)。
(2) の部分では JavaCompiler#getStandardFileManager(DiagnosticListener<? super JavaFileObject> diagnosticListener, Locale locale, Charset charset) メソッドで java.io.File ベースの FileManager である StandardFileManager クラスを取得しています。JavaCompiler#getStandardFileManager メソッドの引数は第一引数から順に、診断メッセージを受け取るためのリスナ、診断メッセージのフォーマットを行う時に適用するロケール、扱うファイルのキャラクタ・セットとなっています。どの引数も null を渡した場合はデフォルトのものが使用されます。
(3) と (4) の部分ではコンパイルするソース・ファイルとコンパイル・オプションをそれぞれ java.io.File の配列、String の配列として用意しています。
(5) の部分では JavaCompiler#getTask メソッドによってコンパイル・タスクを取得しています。JavaCompiler#getTask メソッドの第一引数にはコンパイラの出力メッセージの出力先となる Writer を指定します。null を指定した場合は System.err に出力されます。第二引数には使用する FileManager を指定します。null の場合はコンパイラのデフォルトのものが使用されます。第三引数には診断メッセージを受け取る DiagnosticListener<? super JavaFileObject> を指定します。null の場合はコンパイラのデフォルトのものが使用されます。第四引数にはコンパイル・オプションを Iterable<String> として指定します。コンパイル・オプションを指定しない場合は null を指定することもできます。第五引数にはアノテーション処理のためのクラス名を Iterable<String> として指定します。指定しない場合は null を与えます。第六引数にはコンパイルを行うファイルを Iterable<? extends JavaFileObject> として指定します。指定しない場合は null を与えます。
(6) の部分では取得したコンパイル・タスクを実行し、結果を表示しています。
8.3. ネットワーク・パラメータの取得
今までは MAC アドレスや MTU(Maximum Transmission Unit)などのネットワーク・パラメータを取得する標準の方法はありませんでしたが、java.net.NetworkInterface クラスにこれらのネットワーク・パラメータを取得するためのメソッドが追加されました。以下に NetworkInterface クラスに新しく追加されたメソッドを示します:
- List<InterfaceAddress> getInterfaceAddresses()
- この NetworkInterface のアドレスを含む List を返します。 - Enumeration<NetworkInterface> getSubInterfaces()
- 全てのサブインタフェースを含む Enumeration を返します。 - NetworkInterface getParent()
- 親の NetworkInterface を返します。親が存在しない場合は null を返します。 - byte[] getHardwareAddress()
- ハードウェア・アドレス(MAC アドレス)を返します。 - int getMTU()
- MTU(Maximum Transmission Unit)を返します。 - boolean isLoopback()
- ループバック・インタフェースであるか判定します。 - boolean isPointToPoint()
- Point-to-Point インタフェースであるか判定します。 - boolean isUp()
- ネットワークが接続されているか判定します。 - boolean isVirtual()
- 仮想インタフェース(サブインタフェース)であるか判定します。 - boolean supportsMulticast()
- マルチキャストをサポートしているか判定します。
8.4. CookieManager
Cookie の管理のための抽象クラス java.net.CookieHandler は、今まで実装が提供されていませんでした。Mustang では CookieHandler のデフォルトの実装として java.net.CookieManager が新しく追加されました。また、受け取った Cookie の受け入れ/拒否のポリシーや Cookie の保存先を表すインタフェースも同時に追加されました。
以下に今回追加されたインタフェース/クラスを示します:
- java.net.HttpCookie
- HTTP Cookie を表すクラスです。 - java.net.CookiePolicy
- 受け取った Cookie を受け入れ/拒否のポリシーを表すインタフェースです。 - java.net.CookieStore インタフェース
- Cookie の保存先を表すインタフェースです。 - java.net.CookieManager
- CookieHandler の実装クラスです。
8.5. 軽量 HTTP サーバ
Mustang では HTTP と HTTPS のための軽量サーバが付属しています。関連するクラス/インタフェースは com.sun.net.httpserver パッケージ及び com.sun.net.httpserver.spi パッケージに配置されています。
サーバの役割を担うクラスは com.sun.net.httpserver パッケージの HttpServer 及び HttpsServer 抽象クラスです。それぞれ HTTP 及び HTTPS を扱います。また、サーバの処理に関する主なクラス/インタフェースは以下の通りです:
- HttpServer
- HTTP サーバを表す抽象クラスです。 - HttpContext
- リクエストされた URI に対応する処理を行う HttpHandler のマッピングなどのコンテキスト情報を表す抽象クラスです。 - HttpHandler
- リクエストに対する応答を行うためのインタフェースです。 - HttpExchange
- HTTP リクエスト及びレスポンスを表す抽象クラスです。 - Filter
- HTTP リクエストに対する処理の前後に行う処理(フィルタ)を表す抽象クラスです。
HttpServer の使い方は以下のようになります:
- HttpServer#create メソッドで HttpServer インスタンスを取得する。
- HttpServer#createContext メソッドで HttpContext を作成する。
- HttpContext に Filter の設定などを行う。
- HttpServer#start メソッドでサーバの実行を開始する。
以下に HttpServer の使用例を示します:
import java.io.IOException;
import java.io.OutputStream;
import java.net.InetSocketAddress;
import com.sun.net.httpserver.HttpExchange;
import com.sun.net.httpserver.HttpHandler;
import com.sun.net.httpserver.HttpServer;
public class HttpServerMain
{
public static void main(String[] arguments) throws IOException
{
HttpServer server = HttpServer.create(new InetSocketAddress(8080), 0);
server.createContext("/webapp/", new HelloHttpHandler());
server.start();
}
private static class HelloHttpHandler implements HttpHandler
{
public void handle(HttpExchange exchange) throws IOException
{
StringBuffer buffer = new StringBuffer();
buffer.append("<html>");
buffer.append("<head>");
buffer.append("<title>Hello</title>");
buffer.append("</head>");
buffer.append("<body>");
buffer.append("<h1>Hello</h1>");
buffer.append("</body>");
buffer.append("</html>");
byte[] response = buffer.toString().getBytes();
exchange.sendResponseHeaders(200, response.length);
OutputStream output = exchange.getResponseBody();
output.write(response);
output.close();
}
}
}
このプログラムでは最初に HttpServer#create(InetSocketAddress addr, int backlog) メソッドで HttpServer インスタンスを取得しています。HttpServer#create メソッドの第一引数には接続を待ち受けるアドレス、第二引数には同時接続可能な TCP コネクションの数を指定します(0 以下の場合はシステムのデフォルト)。
次に HttpServer#createContext(String path, HttpHandler handler) メソッドで HttpContext を作成しています。HttpServer#createContext メソッドの第一引数には 「/」から始まる URI、第二引数にはその URI へのリクエストに対応する HttpHandler を指定します。サンプル・コードでは URI に "/webapp/" を指定していますが、この場合は "/webapp/" から始まる URI("/webapp/index.html" や "/webapp123"、"/webapp/abc/def" など)へのリクエストが第二引数に指定した HttpHandler にマッピングされます。また、第二引数には HttpHandler を実装して作成した HelloHttpHandler を指定しています。リクエストに対する処理は HelloHttpHandler#handle(HttpExchange) メソッドで行っています。HelloHttpHandler#handle メソッドでは最初にレスポンスとして返す HTML データを作成し、次に HttpExchange#sendResponseHeaders メソッドでレスポンス・ヘッダとして成功を表すステータス・コード 200 とレスポンス・ボディのバイト数を送信、そしてレスポンス・ボディを出力しています。
最後に HttpServer#start メソッドでサーバの実行を開始しています。サーバを開始後、ブラウザで http://localhost:8080/webapp/ にアクセスすると、HelloHttpHandler#handle メソッドで出力している HTML データがブラウザに表示されます。
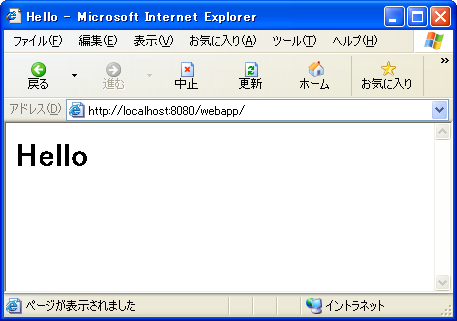
8.6. セキュリティの改善
セキュリティ関係では大規模な変更というものはありませんが、いくつかの小さな改善が行われました。JGSS(Java Generic Security Services)/Kerberos の改善点としては
- 暗号化タイプとして AES128、AES256、RC4-HMAC がサポートされたことによる他の Kerberos 実装(Windows や Solaris 10、MIT Kerberos など)との相互運用性の向上。
- JGSS における SPNEGO(Simple and Protocol GSS-API Negotiation)メカニズム、HTTP における SPNEGO 認証スキームのサポート。
- 最近の Kerberos 仕様で記述される新しい事前認証メカニズムのサポート。
- プラットフォームのネイティブ GSS 実装との統合。
などが行われました。他にも JAAS に LDAP のログイン・モジュールが追加されるなど、いくつかの改善が行われました。
8.7. File クラスの拡張 - ディスク領域/アクセス権限
java.io.File クラスにディスク領域(パーティションのサイズ)を取得するメソッド及びアクセス権限を設定するメソッドが追加されました。
ディスク領域を取得するメソッド
ディスク領域に関するメソッド getTotalSpace、getFreeSpace、getUsableSpace が追加され、それぞれパーティションの合計サイズ、未使用サイズ、有効サイズをバイト単位で得ることができます。
全てのパーティションのサイズを一覧する例:
import java.io.File;
public class FreeSpaceMain
{
public static void main(String[] arguments)
{
for(File root : File.listRoots())
{
System.out.println("[" + root.getPath() + "]");
System.out.println("Total space: " + root.getTotalSpace() + " bytes");
System.out.println("Free space: " + root.getFreeSpace() + " bytes");
System.out.println("Usable space: " + root.getUsableSpace() + " bytes");
System.out.println();
}
}
}
実行例:
[C:\] Total space: 79957946368 bytes Free space: 54127906816 bytes Usable space: 54127906816 bytes [D:\] Total space: 0 bytes Free space: 0 bytes Usable space: 0 bytes
アクセス権限に関するメソッド
File のアクセス権(読み込み/書き込み/実行権限)の設定を行う setWritable、setReadable、setExecutable 及び File が実行可能であることを判定する canExecute が追加されました。
アクセス権限の設定を行うメソッドは、使用している環境がそれに対応している必要があり、アクセス権限の設定に失敗すると false を返します。
File file;
if(!file.setWritable(false)) {
System.out.println("アクセス権限の設定に失敗しました.");
}
8.8. コンソールでのパスワード入力を隠す
コンソールと通信するためのクラス java.io.Console クラスが追加されました。Console クラスではエコー・バックを行わないパスワード入力を行うことができるメソッド readPassword をはじめ、通常の読み取り/書き込みを行うメソッドなどが提供されます。Console クラスでの読み書きは同期化されるので、マルチスレッド環境でも使用することができます。
Console#readPassword メソッドには二つのオーバーロードがあります:
- char[] readPassword()
- char[] readPassword(String fmt, Object... args)
引数を取らないバージョンは単純にパスワード入力を行います。一方、引数を取るバージョンを使用するとパスワード入力の前にメッセージを表示することができます。readPassword(String fmt, Object... args) の引数は String#format(String format, Object... args) メソッドと同じで、フォーマット文字列と変換するオブジェクトを指定します。
以下に、Console#readPassword メソッドによるパスワードの読み取りを行う例を示します:
import java.io.Console;
public class PasswordMain
{
public static void main(String[] arguments)
{
// Console インスタンスは System#console メソッドで取得する.
Console console = System.console();
if(console == null) {
System.out.println("Console is not associated.");
return;
}
// エコー・バックをせずにパスワードを入力する.
char[] password = console.readPassword("%s: ", "password");
System.out.println(password);
}
}
実行例:
password: [[表示されないが「hoge」と入力]] hoge
※注意※
上記コードを Eclipse などの統合開発環境で実行すると、Console インスタンスの取得自体に失敗してしまう場合があります。その場合は、統合開発環境からではなく、直接 java コマンドを使用してプログラムを実行してください。
8.9. Deque
コレクション・フレームワークに Deque(Double-Ended Queue)が追加されました。Deque は「両頭待ち行列」や「両頭待ち Queue」とも呼ばれ、先頭だけではなく末尾にも追加/削除が可能な Queue のことを言います。
Deque に関するインタフェース/クラスを以下に示します:
- java.util.Deque インタフェース(新規追加)
- java.util.ArrayDeque クラス(新規追加)
- java.util.LinckedList クラス(Deque インタフェースを実装するように変更)
- java.util.concurrent.BlockingDeque インタフェース(新規追加)
- java.util.concurrent.LinkedBlockingDeque クラス(新規追加)
Deque インタフェースでは要素へアクセスするためのメソッドとして以下のものが定義されています:
| 先頭要素 | 末尾要素 | |||
|---|---|---|---|---|
| 追加 | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| 削除 | removeFirst() | pollFirst() | removeLast() | pollLast() |
| 参照 | getFirst() | peekFirst() | getLast() | peekLast() |
addFirst(e) と offerFirst() のように一つの分類に二つのメソッドがありますが、これらは Deque の容量が足りない場合や要素が無い場合の動作が異なります。以下にその違いを説明します:
- 要素を追加するときに Deque の容量が足りない場合
- addFirst/addLast メソッド - IllegalStateException を投げる。
- offerFirst/offerLast メソッド - false を返す。
- 要素を削除するときに Deque が空の場合
- removeFirst/removeLast メソッド - NoSuchElementException を投げる。
- pollFirst/pollLast メソッド - null を返す。
- 要素を参照するときに Deque が空の場合
- getFirst/getLast メソッド - NoSuchElementException を投げる。
- peekFirst/peekLast メソッド - null を返す。
8.10. NavigableSet/NavigableMap
順方向アクセス/逆方向アクセスや指定範囲の抜き出しなどを行うことができる Set/Map として java.util.NavigableSet 及び java.util.NavigableMap インタフェースが追加されました。NavigableSet は java.util.SortedSet、NavigableMap は java.util.SortedMap を継承しています。
NavigableSet の使用例:
import java.util.NavigableSet;
import java.util.TreeSet;
public class NavigableSetMain
{
public static void main(String[] arguments)
{
NavigableSet<Integer> navigableSet = new TreeSet<Integer>();
// 0 以上 9 以下の整数を追加.
for(int i = 0; i < 10; i++) {
navigableSet.add(i);
}
// 全要素を表示.
System.out.print("全要素 : ");
for(int value : navigableSet) {
System.out.print(value + " ");
}
System.out.println();
// 5 超過/以上/以下/未満の要素を取得.
System.out.println("higher(5) : " + navigableSet.higher(5));
System.out.println("ceiling(5) : " + navigableSet.ceiling(5));
System.out.println("floor(5) : " + navigableSet.floor(5));
System.out.println("lower(5) : " + navigableSet.lower(5));
// 3 以上 7 未満の要素を抜き出す.
NavigableSet<Integer> subSet = navigableSet.subSet(3, true, 7, false);
System.out.print("[3, 7) の要素 : ");
for(int value : subSet) {
System.out.print(value + " ");
}
System.out.println();
}
}
出力結果:
全要素 : 0 1 2 3 4 5 6 7 8 9 higher(5) : 6 ceiling(5) : 5 floor(5) : 5 lower(5) : 4 [3, 7) の要素 : 3 4 5 6
NavigableSet
以下に NavigableSet に関するインタフェース/クラスを示します:
- java.util.NavigableSet インタフェース(新規追加)
- java.util.TreeSet クラス(NavigableSet インタフェースを実装するように変更)
- java.util.concurrent.ConcurrentSkipListSet クラス(新規追加)
NavigableSet には要素にアクセスするための様々なメソッドが含まれています。まず、Iterator 関係では順方向及び逆方向に走査するための Iterator を返すメソッドがあります:
- Iterator<E> iterator()
- 順方向に走査するための Iterator を返します。 - Iterator<E> descendingIterator()
- 逆方向に走査するための Iterator を返します。
要素を取得するメソッドには以下のものが提供されています:
- E higher(E e)
- 要素の中から e より大きい最小の値を返します。存在しない場合は null を返します。 - E ceiling(E e)
- 要素の中から e 以上の最小の値を返します。存在しない場合は null を返します。 - E floor(E e)
- 要素の中から e 以下の最大の値を返します。存在しない場合は null を返します。 - E lower(E e)
- 要素の中から e 未満の最大の値を返します。存在しない場合は null を返します。 - E pollFirst()
- 最小値を持つ要素を返すと同時に NavigableSet から削除します。NavigableSet が空の場合は null を返します。 - E pollLast()
- 最大値を持つ要素を返すと同時に NavigableSet から削除します。NavigableSet が空の場合は null を返します。
また、元の NavigableSet から新しい NavigableSet を作成するメソッドとして以下のものがあります:
- NavigableSet<E> descendingSet()
- 順序付けが反対で同じ要素を持つ NavigableSet を返します。 - NavigableSet<E> headSet(E toElement, boolean inclusive)
- toElement 以下(inclusive が true の場合)または toElement 未満(inclusive が false の場合)の値を含む NavigableSet を返します。 - NavigableSet<E> tailSet(E fromElement, boolean inclusive)
- fromElement 以上(inclusive が true の場合)または fromElement 超過(inclusive が false の場合)の値を含む NavigableSet を返します。 - NavigableSet<E> subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive)
- fromElement 以上(fromInclusive が true)または fromElement 超過(fromInclusive が false)、なおかつ toElement 以下(toInclusive が true)または toElement 未満(toInclusive が false)の値を含む NavigableSet を返します。
NavigableMap
以下に NavigableMap に関するインタフェース/クラスを示します:
- java.util.NavigableMap インタフェース(新規追加)
- java.util.TreeMap クラス(NavigableMap インタフェースを実装するように変更)
- java.util.concurrent.ConcurrentNavigableMap インタフェース(新規追加)
- java.util.concurrent.ConcurrentSkipListMap クラス(新規追加)
NavigableSet 同様、NavigableMap にも要素にアクセスするための様々なメソッドが含まれています。
NavigableMap からエントリを取得するメソッドには以下のものがあります:
- Map.Entry<K,V> higherEntry(K key)
- key よりも大きい最小のキー値を持つエントリを返します。該当するエントリが存在しない場合は null を返します。 - Map.Entry<K,V> ceilingEntry(K key)
- key 以上の最小のキー値を持つエントリを返します。該当するエントリが存在しない場合は null を返します。 - Map.Entry<K,V> floorEntry(K key)
- key よりも以下の最大のキー値を持つエントリを返します。該当するエントリが存在しない場合は null を返します。 - Map.Entry<K,V> lowerEntry(K key)
- key よりも未満の最大のキー値を持つエントリを返します。該当するエントリが存在しない場合は null を返します。 - Map.Entry<K,V> firstEntry()
- 最小のキー値を持つエントリを返します。NavigableMap が空の場合は null を返します。 - Map.Entry<K,V> pollFirstEntry()
- 最小のキー値を持つエントリを返すと同時に NavigableMap から削除します。NavigableMap が空の場合は null を返します。 - Map.Entry<K,V> lastEntry()
- 最大のキー値を持つエントリを返します。NavigableMap が空の場合は null を返します。 - Map.Entry<K,V> pollLastEntry()
- 最大のキー値を持つエントリを返すと同時に NavigableMap から削除します。NavigableMap が空の場合は null を返します。
ここでは戻り値が Map.Entry<K,V> であるメソッドだけを示しましたが、higherKey や floorKey など、戻り値が Map のキーであるメソッドも含まれています。
元の NavigableMap をもとに新しい NavigableMap を作成するメソッドには以下のものがあります:
- NavigableMap<K,V> descendingMap()
- 順序付けが反対で同じ要素を持つ NavigableMap を返します。 - NavigableMap<K,V> headMap(K toKey, boolean inclusive)
- toKey 以下(inclusive が true の場合)または toKey 未満(inclusive が false の場合)であるキー値を持つエントリを含む NavigableMap を返します。 - NavigableMap<K,V> tailMap(K fromKey, boolean inclusive)
- fromkey 以上(inclusive が true の場合)または fromKey 超過(fromInclusive が false の場合)であるのキー値を持つエントリを含む NavigableMap を返します。 - NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive)
- fromKey 以上(fromInclusive が true)または fromKey 超過(fromInclusive が false)、なおかつ toKey 以下(toInclusive が true)または toKey 未満(toInclusive が false)であるエントリを含む NavigableMap を返します。
他にも、NavigableMap の各エントリのキーを含む NavigableSet を返すメソッドも含まれています:
- NavigableSet<K> navigableKeySet()
- 各エントリのキーを含む NavigableSet を返します。 - NavigableSet<K> descendingKeySet()
- 各エントリのキーを含み、反対の順序付けを持つ NavigableSet を返します。
8.11. 配列の縮小コピー/拡大コピー/スライス
java.util.Arrays クラスに配列のコピーを行うメソッドが追加されました。今までは配列のコピーを行うために System#arraycopy メソッドが使用されてきましたが、Arrays クラスに新しく加えられた copyOf 及び copyOfRange メソッドにより、System#arraycopy メソッドよりも使い勝手の良いインタフェースが提供されます。copyOf 及び copyOfRange メソッドを使用すると、配列の縮小コピー、拡大コピー及びスライス(指定範囲の抜き出し)を行うことができます。
サンプル・コード:
String[] original = { "a", "b", "c", "d" };
// 縮小コピー
String[] shrinked = Arrays.copyOf(original, 2);
System.out.println(Arrays.toString(shrinked));
// 拡大コピー
String[] grown = Arrays.copyOf(original, 7);
System.out.println(Arrays.toString(grown));
// スライス
String[] sliced = Arrays.copyOfRange(original, 1, 3);
System.out.println(Arrays.toString(sliced));
出力結果:
[a, b] [a, b, c, d, null, null, null] [b, c]
copyOf メソッド
copyOf メソッドを使用すると、配列のコピーと同時にサイズの変更を行うことができます。copyOf メソッドにはいくつかのオーバーロードが存在しますが、使い方に関しては以下の二種類のメソッドに代表されます:
- static <T> T[] copyOf(T[] original, int newLength)
- static <T,U> U[] copyOf(T[] original, int newLength, Class<? extends T[]> newType)
一つ目の copyOf(T[] original, int newLength) メソッドは、長さ newLength の配列に original の要素をコピーして返します。このとき、newLength が original.length よりも小さい場合は newLength 分だけがコピーされ、残りの要素は切り捨てられます。反対に newLength が original.length よりも大きい場合は newLength 分だけコピーされ、残りの要素に null が設定された配列が返されます。また、一つ目の形式にはプリミティブ型のオーバーロードも存在します。
二つ目の copyOf(T[] original, int newLength, Class<? extends T[]> newType) メソッドは、copyOf(T[] original, int newLength) メソッドに似ていますが、内部で型変換が行われ、newType に指定した型の配列を返します。
copyOfRange メソッド
copyOfRange メソッドは配列のスライス(指定範囲の抜き出し)を行います。copyOf メソッドとの決定的な違いは、copyOfRange メソッドはあくまでも配列のスライスを行うのであって、元の配列より大きなサイズにすることができないという点です。
copyOfRange メソッドにもいくつかのオーバーロードが存在しますが、使い方に関しては以下の二種類のメソッドに代表されます:
- static <T> copyOfRange(T[] original, int from, int to)
- static <T,U> T[] copyOfRange(U[] original, int from, int to, Class<? extends T[]> newType)
一つ目の copyOfRange(T[] original, int from, int to) メソッドは original の from 番目から to-1 番目の要素を抜き出します。二つ目の copyOfRange(U[] original, int from, int to, Class<? extends T[]> newType) メソッドは、それに加えて newType に指定した型への変換も行います。どちらのメソッドも from や to に original.length よりも大きい値を指定すると ArrayIndexOutOfBoundsException が投げられます。
8.12. コア・ライブラリ その他の改善
他にもコア・ライブラリでは色々な改善が行われました。一つ一つを取り上げると膨大な量になってしまうので、いくつかピックアップして紹介します:
- String#isEmpty メソッド
- String クラスに文字列が空であることを判定する isEmpty メソッドが追加されました。今まで「if(string.length() == 0) { ... } 」と記述していたところを「if(string.isEmpty()) { ... } 」と書くことができるため、可読性が向上します。 - Scanner#reset メソッド
- java.util.Scanner クラスに reset メソッドが追加されました。reset メソッドは useDelimiter、useLocale、useRadix メソッドによって行われた設定をリセットします。 - Collections#newSetFromMap メソッド
- java.util.Collections クラスに指定した Map をバックエンドに持つ Set を作成するメソッド newSetFromMap が追加されました。通常は TreeSet と TreeMap のように同じ特性の Set と Map の両方が提供されていますが、そうでない場合(Map しか提供されていない場合)でも、Map と同じ特性(順序付け、並列性、パフォーマンス)を持つ Set を作成することができます。 - Collections#asLifoQueue メソッド
- java.util.Collections クラスに、Deque の LIFO(Last-In-First-Out)の Queue としてのビューを返すメソッド asLifoQueue が追加されました。 - TimeUnit のコンビニエンス・メソッド
- java.util.concurrent.TimeUnit クラスに toMinutes、toHours、toDays メソッドが追加されました。これらはそれぞれ TimeUnit.MINUTE、TimeUnit.HOURS、TimeUnit.DAYS の convert メソッドを使用することと等価です。 - AbstractQueuedLongSynchronizer
- java.util.concurrent.locks.AbstractQueuedSynchronizer の内部表現に long 型を用いるバージョンとして、java.util.concurrent.locks.AbstractQueuedLongSynchronizer 抽象クラスが追加されました。 - RunnableFuture インタフェース
- Runnable と java.util.concurrent.Future を組み合わせたインタフェース java.util.concurrent.RunnableFuture が追加されました。また、Runnable と java.util.concurrent.ScheduledFuture を組み合わせたインタフェース java.util.concurrent.RunnableScheduledFuture も追加されました。 - etc...
まとめ
今回で Java SE 6 "Mustang" の解説はおしまいです。J2SE 5.0 "Tiger" が登場したころを思い出すと、Generics やアノテーション、拡張 for 文など言語レベルの変更があり目を引きました。今回の Mustang では言語レベルの変更は無かったものの、スクリプティング機能の導入やネイティブ・デスクトップとの統合、JDBC 4.0 の EoD、国際化対応の強化、XML など周辺技術との連携の強化、管理機能の改善などが行われました。開発効率を向上させる新機能の登場に加えて、コア・ライブラリの改善など言語の底力の向上もしっかりと図られています。
Tiger の登場から約二年経っての Mustang の登場でしたが、今後は 18 〜 24 ヶ月間隔でコンスタントにメジャー・バージョンアップを行うことが予定されています。そして早くも Java SE 7 "Dolphin" へ向けた活動も開始されています(https://jdk7.dev.java.net/)。まだ先の話であり、確定していることは多くありませんが、XML リテラルやクロージャ、モジュール機能の導入など言語レベルの変更を伴う機能追加が検討されているそうで、今後とも Java の進化には目が離せそうにありません。
