想像してみてください。今この瞬間……
- 悪意のないユーザがF5キーに手を添えたまま、うたた寝してしまうかもしれません
- 巨大ニュースサイトにリンクが張られ、大量のユーザが流れ込もうとしているかもしれません
- エンジニアが不注意で埋め込んだ不具合がプロセスを落とし、パフォーマンステストを怠ったSQLがCPUやIOを占有することもあるでしょう
- ミドルウェアやOS、ネットワーク機器のファームウェアだって完ぺきではありません
- サーバのメモリを狂わせるため、宇宙線は虎視眈々と隙をうかかがっています
数え上げればきりがない程、サーバ達は常に危機に晒されているのです。
一台のサーバやネットワーク機器の障害で大切なシステムをダウンさせてしまうわけにはいきません。
深夜に障害を告げ鳴り響く携帯電話に叩き起こされ、やっとの思いでシステムを復旧させた朝、関係各所に平謝りしながらクライアントへの障害報告書を用意する、なんて一日を迎えるのは遠慮したいところです。
このように、一つの障害によりシステムの停止を招いてしまうポイントを単一障害点(SPOF - Single Point of Failure)と呼びます。
脱SPOFに向けて
SPOFをなくすための基本戦略は、システムを冗長化(多重化)させることです。
冗長化を目的ごとに大きく分類すると、下記の2つに分けられます。
- 障害時に処理を迂回させるためのバックアップを用意するActive/Standby構成
- 高負荷時の処理能力不足を回避するため、ロードバランサ(LB)を用いて負荷分散を行うActive/Active構成
これらは様々なレイヤ、プロトコルで実装され、堅牢なシステムは幾重にも張り巡らされた冗長構成の庇護の元運用されているのです。
遥か古から、数多のエンジニア達が(平穏と安眠を手に入れる)ステークホルダの利益を守るため、冗長化の手法を編み出し続けてきました。
本稿は、そんな先人たちの知恵の一部をOSI参照モデルのレイヤごとにまとめたものとなります。
L2 データリンク層
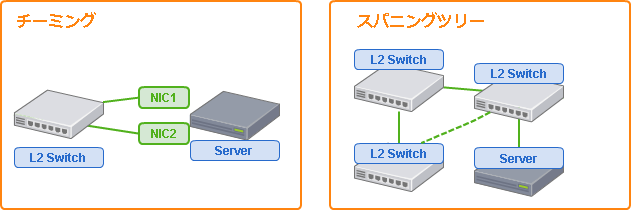
チーミング
チーミングは複数のネットワークインタフェースカード(NIC)を束ねて仮想的に一つのNICとして扱う機能で、主にNICやケーブルの障害対策として利用されます。
チーミングには大きく分類して以下の3種類の動作モードがあり、NICや接続先のスイッチの制約によって利用できるモードや細かな機能が異なります。
- フォールトトレランス(Fault Tolerance)
- Active/Standbyの冗長構成をとります。プライマリとスタンバイのNICを設定し、NICの障害を検知するとスタンバイのNICを利用して通信を行います。
- ロードバランシング(Load Balancing)
- Active/Activeの冗長構成をとります。
1対多の通信での送信スループットを向上させます。 - リンクアグリゲーション(Link Aggregation)
- Active/Activeの冗長構成をとります。
ロードバランスと違い、1対多の通信での送受信スループットを向上させます。
スパニングツリー
チーミングは主にサーバのNIC、ポート、ケーブルの障害に対しての冗長化を目的としますが、スパニングツリーはスイッチ間のネットワーク経路の冗長化のために利用されます。
通常、Ethernetでスイッチからの経路が自身の別のポートに戻るような接続を行うと、ブロードキャストフレームがループすることにより、正常な通信ができないばかりでなく、ネットワークに接続された機器に大きな障害をもたらしてしまいます。
スパニングツリーを利用すると、本来ループする経路の一部を利用しない状態に保つことができ、障害時にはその経路を利用して通信を行うことができます。
L3 ネットワーク層

VRRP
VRRPはデフォルトゲートウェイの冗長化手段として、Active/Standbyのルータを構成する際に利用されます。VRRPでは実アドレスと異なるVIP(仮想IPアドレス)を利用してルータを構成し、ルータを利用するクライアントはデフォルトゲートウェイにVIPを指定します。
通常時はマスタルータがVIPへの処理を行いますが、マスタルータのダウンを検知した場合、バックアップルータがGARP(Gratuitous ARP)リクエストを送出することでVIPに対するルーティング処理の引継ぎを行います。
ルーティングプロトコル ECMPとIP Anycast
OSPFやBGPといったルーティングプロトコルを利用すると、ルーティングによる負荷分散構成をとることができるようになります。
これらのルーティングプロトコルでは、ルータ間で経路情報を交換し合うことにより、アドレス帯域への経路を複数持つことができます。
通常はコストベースのルーティングにより、最もコストの低い(≒近い)経路を選択することになります。
この時、コストを同一に設定した経路を複数用意することによって通信経路を分散することができ、これをECMP(Equal Cost Multi Path)と呼びます。
また、複数のサーバが同一の(Unicast)アドレスをルータに告知すると、ルータは通信時にコスト計算によって1つの経路(ポート)を選択して転送します。
これをIP Anycast と呼び、図のようにECMPとIP Anycastを併用するとアプリケーションサーバの負荷分散に利用することができます。
ECMPで負荷分散を行う際、宛先の選定を単純なラウンドロビン(各経路を順番に利用)とした場合、パケット単位で別々のポートに転送され、受信側でTCPメッセージを結合できないため正常な通信が行えません。
この問題を解決するために、フロー単位で同一の宛先を利用する Per-flow ECMP という技術が利用されます。フローを識別する要素はルータによって異なりますが、送信元・宛先 アドレスのハッシュ値などが利用されます。
L4 トランスポート層
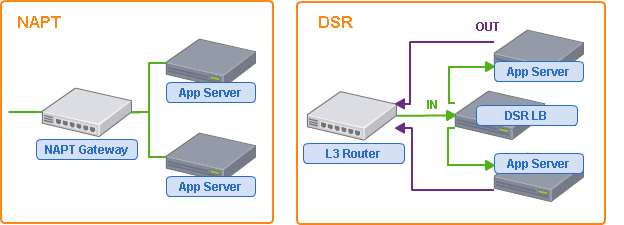
NAPT
NAPT はネットワークアドレスポート変換(Network Address Port Translation)の略で、グローバルIPアドレスを持たないネットワークからグローバルネットワークに接続する手段として企業から一般家庭まで広く利用されています。
NAPTルータは外部ネットワークからの接続を受けつけた際、内部ネットワーク向けにパケットを書き換えて転送することにより実現され、LBとして利用する際は、内部ネットワーク側の接続を複数の宛先に振り分けることで負荷分散を行います。
DSR
DSRはDirect Server Returnの略で、代表的な実装としてLinuxのLVSがあげられます。
DSRはパフォーマンスを向上させるため、戻りパケットに関与しない負荷分散の方式です。
DSRを行うLBは、あらかじめ設定したVIP(仮想IPアドレス)を持ち、実際にリクエストを処理する下流サーバも同じVIPを処理できるように設定します。
DSR LBがVIP宛のパケットを受信すると、下流サーバのMACアドレス宛に分散させて送信します。この際、IPアドレスなど、L3レイヤでのパケットの変換は行われないため、受信した下流サーバは戻りパケットをDSR LB を経由せず、直接ルータに返却することができます。
WEBサービスにおける送受信パケットの比率は、受信に比べて送信(戻り)パケットの方が圧倒的に多いのが一般的です。DSRではこの送信パケットの処理を行う必要がないため、NAPTなどを利用した負荷分散と比べて高いパフォーマンスを得ることができます。
デメリットとして下流サーバのVIPやARP(あるいはIPIPトンネル)の設定などが必要なため仕組みが複雑になりがちな点があげられます。
L7 アプリケーション層
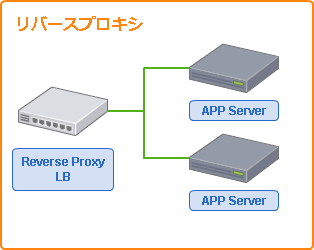
リバースプロキシ
L7レイヤになると各アプリケーション層のプロトコルごとに専用の処理を行うことになるため、振り分け処理の自由度が一気に高くなります。
このレイヤでの負荷分散は、アプリケーション層での通信を受け付け、アプリケーションサーバへ振り分けるリバースプロキシが代表格です。
ロードバランサとしての動作は、L4レイヤで紹介したNAPT LBにアプリケーション層の通信内容に応じた変換処理を追加できる機能として見ることができます。
プロトコルごとの実装が必要となる分、機能は多岐にわたります。特にHTTP/HTTPSの実装が多く存在しますが、SMTPやIMAPなどのリバースプロキシも存在します。
レスポンスのキャッシュ、静的コンテンツの返却、SSLのオフロード、Sticky Session(CookieのセッションIDによる振り分け先固定化)など、多くの機能を内包できるため、ハードウェアからソフトウェアまで様々な実装が存在します。
リバースプロキシを実装する代表的なOSSとしてApache HTTP Server, nginx, HAProxy, h2o などがあげられます。
接続元IPアドレスを取得することが難しいというデメリットがありますが、HTTPではX-Forwarded-Forヘッダなどの追加ヘッダを用いて接続元IPを引き継ぐなどの回避策が存在します。
その他
DNS (L3)
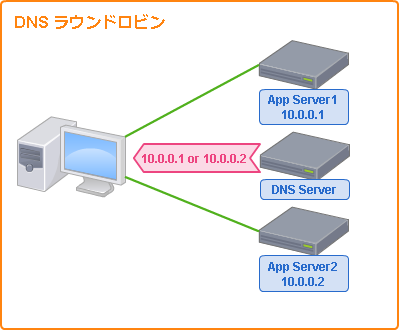
これまで紹介した手法は、クライアントからのIP通信を冗長化し、負荷を分散することに目的としていますが、クライアントからのアプリケーションへの通信が始まる一歩手前での手法も存在します。
今日のインターネットを利用したシステムの通信は、大抵の場合、DNSによる名前解決を行うことから始まります。
この名前解決の際に、返却するIPアドレスを切り替えることにより負荷分散や冗長化を行うことができるのです。
冗長化対象がIPプロトコルになるためレイヤとしてはL3に分類されると思います。ただ、その他のL3冗長化手法とはアプローチがかなり異なるため、その他として紹介することにしました。
DNSサーバに複数のIPアドレスを登録し、順番に切り替えながら返却する方法はDNSラウンドロビンと呼ばれます。
障害があった場合に返却するIPアドレスを切り替えるDNSフェイルオーバーや、DNSへの接続経路をもとに最適なサーバのIPアドレスを返却するLatency RoutingやGeo Routingなどといった機能も利用されています。
DNSサーバさえあれば別途機器を導入することなく運用可能で特別なオーバーヘッドもなく、通信経路を用意せずとも異なるロケーション(データセンター)への負荷分散が可能であるなどのメリットがあり、広く利用されています。
デメリットとして、DNSは名前解決の経路上でキャッシュされることが多いため、変更の反映が必ずしもリアルタイムではない、といった問題があります。
Multipath TCP (L4)
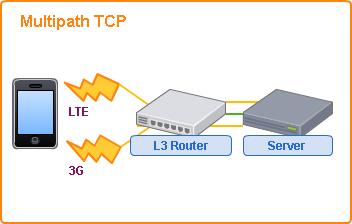
Multipath TCPは複数のTCPセッションを、仮想的に一つのTCPセッションとして扱うことができるプロトコルです。
複数のセッションを併用することによる通信速度の高速化と、片側のセッションが切断してもTCPセッションを維持できるというメリットがあるため、スマートフォンで3GとLTE回線を併用する用途などで利用されています。
Multipath TCPに対応したネットワーク機器を利用しない場合、通常のTCP接続としてフォールバックされるようになっているため、既存のTCPと併用して利用することができます。もちろんこの場合はMultipath TCPのメリットを享受することはできません。
スマートフォンの例で挙げたように、主にクライアントからサーバまでの経路を冗長化するために利用される技術のため、サーバサイドでの冗長化や負荷分散に利用するには敷居が高いと言えるでしょう。最近利用され始めた新しい技術なので、今後対応機器が増えてくることで利用する機会が現れるかもしれません。
シミュレーションしてみる
ここまで様々なレイヤの冗長化、負荷分散の手法を紹介しましたが、これらいずれの技術も銀の弾丸ではなく、要件に応じて適切に選択し、組み合わせた設計が必要になります。
……と教科書的に締めてしまってもつまらないので、オンプレミスでのWEBシステムを構築する想定で冗長構成のシミュレーションを行ってみたいと思います。
比較的汎用的な構成になるよう意識したつもりですが、あくまでも筆者の独断と偏見による一例としてとらえていただけると幸いです。
基本的な方針を以下の2点とし、アーキテクチャを検討してみました。
・障害により致命的な影響を及ぼすネットワーク機器はActive/Standbyの冗長構成
・障害率が高く、高負荷になりがちなアプリケーションサーバはLBを用いて負荷分散
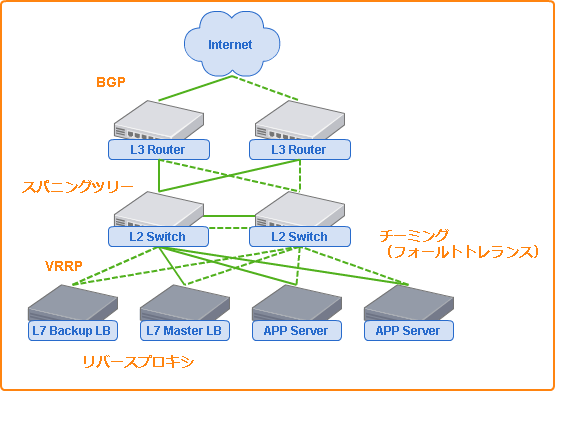
ネットワーク機器の障害は深刻なシステム停止を招き、リモートメンテナンスを行えない状況さえ引き起こすため対策は必須となります。
スイッチ間はスパニングツリーで冗長化し、接続する各機器をチーミングにより複数スイッチと接続するようにすればよいでしょう。
外部ネットワークと接続するルータについては、上流のルータの要件に合わせて構成を検討しましょう。
可能であれば、緊急時の管理用の経路となる回線やネットワーク機器を別途用意しておくことをお勧めします。
アプリケーションサーバの負荷分散ではNAPT、DSR、リバースプロキシが候補となりますが、導入の容易さと機能の豊富さからL7レイヤのリバースプロキシをLBとして設置するのがおすすめです。
負荷分散と同時に、コンテンツのキャッシュやSSLオフロードなどによりアプリケーションサーバの負荷を大きく下げることができます。
LBは用途に応じて多段で設置することもできるため、動画配信など戻りトラフィックが大きなシステムでは上流へのDSR LBの設置などを検討すると良さそうです。
最上流のLBの冗長化にはVRRPを利用するのが手っ取り早いですが、LBが1台の構成ではパフォーマンスが不足する場合、ECMPによる負荷分散が利用できそうです。
AWSの場合
比較対象としてAWS上での冗長構成についても検討してみました。
AZに分散させたEC2の上流にELB(またはALB)を設置するだけで、L7のリバースプロキシによる負荷分散、SSLオフロード、DNSによるデータセンタ間の冗長構成もとってくれます。
AMIを作成しAutoScalingを設定しておけばインスタンス障害時のフェイルオーバーや負荷増大時の動的スケールアウト(サーバの追加)が可能です。
キャッシュや静的コンテンツの配信を重視する場合は上流にCloudFrontとS3を置けばよいでしょう。
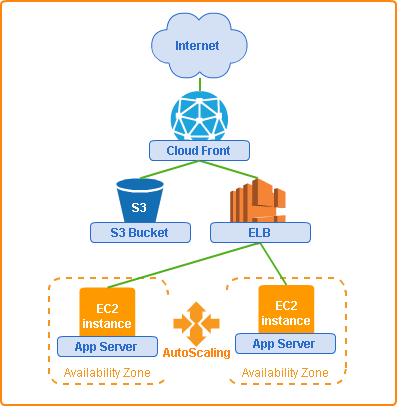
オンプレミスの図には入れなかった、静的コンテンツやキャッシュ(CloudFront + S3)まで入れたのに、ずいぶんすっきりした図になりました。
クラウドサービスを利用する場合、ネットワークの低レベルな部分やハードウェアについてはサービス側で提供してくれる上、設定も管理画面やSDKから容易に行えます。
ただし、考慮しておきたいのは、クラウドサービスを利用するだけで安定したシステムがつくれるわけではないということです。
AWSに代表される大規模なクラウドサービスでは、数多くのハードウェアとそれを制御するソフトウェアにより運用され、多種多様なトラフィックを処理し続けています。
ハードウェアの障害による局所的な障害や、メンテナンスにより仮想マシンの再起動が必要になる場合もあり、時として大規模な障害が発生してしまうこともあります。
筆者の私見ではありますが、クラウドサービスを利用することでハードウェアを意識しなくなった分、利用者は用意されたサービスを利用して堅牢なシステムを構築することに注力する必要があり、またそこに注力できることにメリットがあると考えています。
最後に
本稿ではシステムを安定して稼働させるための冗長化について書いてきましたが、殆どのシステムにおいて、最優先とすべき永続化データの冗長化について触れていません。
RDBやファイルシステムなど利用しているミドルウェア・ストレージに応じて種々方法が異なるため割愛しましたが、データを失ってしまうとシステムの存続自体が困難になってしまうため、最優先で担保する必要があるでしょう。
筆者は業務でオンプレミスとAWSのハイブリッドで動いているシステムの実装や運用を行っているのですが、どちら側にも解決したい可用性の課題は存在するわけで……。
堅牢なシステムを作るには、まずは世の中の堅牢なシステムを学ぶことから始めるべきだと思い立ってネットを漁りだしました。
そんな時見つけたのがこちら(ロードバランサのアーキテクチャ色々)の記事で、MicrosoftやFacebookなどの大規模なサービスの構成にワクワクすると同時に、自分のネットワークレイヤの知識不足を痛感した次第です。
応用を考えるには、まず基礎技術を咀嚼しないと! ということで本記事を書くに至りました。
色々調べて改めて感じましたが、ネットワークは楽しいですね。
ネットワークを知ることで、可用性やパフォーマンスについてちょっとだけ引き出しが広がった気がします(気のせい)。
これからはもっとネットワークで遊んでいこうと思います。
可用性についてのネタはもう少し引っ張ろうと思うので、近いうちに何本か記事を書きたいと思います。
