はじめまして、増田です。
これは TECHSCORE Advent Calendar 2015 の5日目の記事です。
ところでみなさん、非同期処理やってますかー?
…
今作っているプロダクトは、非同期処理で恩恵を授かりまくっています。今回の記事では、私の関わっているプロジェクトで非同期処理をどんな用途に使っているのか、また、どのような恩恵があったのかをお伝えして、非同期処理に少しでも関心を持っていただけたらと思います。
非同期処理とは。
非同期処理と聞いてどんな用途をイメージされますか?
ちょっと重たい処理をバックエンドで処理したり、メールを送る用途に使ったりする例はよく非同期処理の説明で出てくる例ですが、我々はもうちょっと別の用途で使っています。その前に、用語のおさらいをしておきます。
- ジョブ
- 非同期処理で処理する仕事
- キュー
- ジョブが蓄積される入れ物
- ワーカー
- ジョブを処理するプロセス
キューからジョブを取り出し順次処理を行う。
- ジョブを処理するプロセス
1. 攻めのデータ取得
昨年、外部サイトの情報を定期的に取得しダッシュボードに表示するちびデータというアプリケーションを作成しました。使い方は簡単です。利用者はダッシュボードに表示したいサービスを選択するだけです。



このシステムが選択された外部サービスのAPIからデータを定期的に取得し、ダッシュボードに数値やグラフが表示します。このデータを取得する部分で非同期処理を使っているのです。例えば、Google AnalyticsのAPIに定期的に問い合わせることで、現在のサイトへのアクセス状況をダッシュボードに表示するわけです。このダッシュボードは利用者ごと、さらにはパネル1ずつが問い合わせのパラメータが異なるので、大量のジョブが登録されています。ジョブは次に問い合わせる時間と、問い合わせ先を保持しているので、ワーカーは時間になったらジョブを叩き起こして、それぞれのデータ取得しに行きます。
まさに攻め。
2. 大量のデータを捌く
現在作成しているアプリケーションは、ユーザのメールに関する操作の全イベントをWebhookとして外部サービスからリクエストを受信し分析を行った結果、DBに保存するような処理を行っている部分があります。Webhookは毎秒数百リクエストと大量にデータがポストされてくる想定で、その情報を取りこぼすこと無く捌く必要がありました。
データがポストされた時点で、処理を行っていたのではアクセスがバーストした際にとても間に合いません。 そこで、飛んできたリクエストを非同期処理としてジョブをバックエンドにバンバン登録して処理することで遅延することなく処理が行えるようにしました。
また、ジョブを登録する処理は、とてもコストが低いのでスペックの低いマシンをフロントに並べることでスケールアウト可能です。安上がりです。
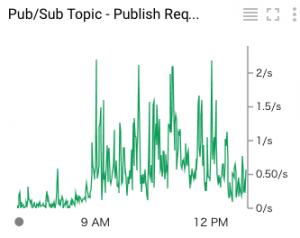
Google Cloud PlatformのPubSubからWebhookで大量のリクエストがPOSTされてくる。
何故美味しいの?
1つ目に、ジョブを処理するワーカーを増やすことで簡単に処理能力がスケールします。
バックエンドに投入されたジョブは、ジョブを処理するワーカーが順次処理を行っていきます。ジョブが投入されるスピードがジョブを処理するスピードよりも早くなった場合、ワーカーの数を増やすことで処理が追いつくようになるのです。 普通じゃん!と思われるかもしれませんが、結構重要なんです。監視のポイントとして、未処理のジョブ数を監視しているので、アラートがあがればワーカーを投入する仕組みにしています。
昨今のIaaS、PaaSのおかげで湯水のごとくサーバの調達が便利になりました。そのおかげで、ボタン一つでワーカーを増やすことができるようになったのです。 実際、今のプロダクトでもHerokuとAWS上のワーカーをボタン一つで調整しています。
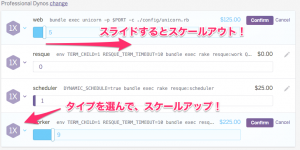
Herokuの管理画面。スライドバーの操作で、簡単にインスタンス数を変更できる。
心にゆとり。
2つ目にキューがバッファになってくれているおかげで運用に余裕が生まれます。
キューに溜まったジョブは消えてなくならないので、ワーカーの運用は無停止にこだわる必要がありません。大量のリクエストが来る中、Herokuの1日1回の自動再起動や、AWSのインスタンスタイプ変更と言った作業も問題なく行えます。
疎結合によってアーキテクチャに自由度が生まれる。
レイヤーが分離しているので、仕組みを差し替える事ができます。
例えば、キューの部分をRedisを使って運用していたのですが、運用が面倒だということでフルマネージドなSQSに移行したり、最初は書き慣れたRubyで作ったのですが、ワーカー部分で処理速度が求められるようになったので、Scalaでワーカーを書いたりと、構成に自由度が生まれます。 これでまた、無理難題な要望に答えられるぞッ!
いかがでしたか?
今更感はある内容ですが、我々のチームは非同期処理で幸せになれました。
言語やフレームワークによって、導入のしやすさはまちまちだとは思いますが、
Ruby on Railsは最近のバージョンになってから、非同期処理のサポートが強化されました。これも何かのご縁だと思います。これを機にみなさんも非同期処理はじめてみませんか??
