こんにちは、馬場です。
はい。無事完走しました!
報告がだいぶ遅くなりましたが、第9週、第10週の内容と講義全体の総括をしたいと思います。
16. 異常検出
今回は異常なデータを検出するアルゴリズムです。例えば、洪水などの災害の検知や製品を作る上で異常なものを除く場合に利用します。まず、データが平均μ、分散σの正規分布だと仮定します。この平均や分散は、学習データから算出します。すると、この情報から特定のデータの出現確率が求められます。そして出現確率があるしきい値εよりも小さい場合に、異常と判定するのです。
異常検出モデルを作成する場合にデータを収集した場合、当然異常データが含まれているとしてもほんのわずかでしょう(だって異常なのですから)。このデータをクロスバリデーション用のデータと学習データに分ける場合、学習データは正常データのみで作成し、クロスバリデーションデータやテストデータに、異常データを含め評価するとよいでしょう。また、しきい値εや確率モデルの評価は、F1-scoreなどを計算して評価するのがよいです。
それでは、この異常検出モデルとロジスティック回帰などの教師あり学習を、どう使い分けたらいいでしょう。もし、学習データの中に「異常」のデータがほんのわずかしか含まれてなく、異常データに共通する特徴を見つけることが難しい場合は、異常検出モデルを適用するのがよいでしょう。逆に異常データと正常データ、両方が十分な数存在する場合は教師あり学習を試してみる方がよい結果がでます。
講義では、異常検出モデルを適用する場合の変数の選び方についても言及していました。変数が正規分布していないようならば、0.01乗する、logをとるなどの加工をして正規分布するような新しい変数に変換する必要があります。また、今ある変数だけでは「異常」データの発現確率が高くなってしまう場合は、新たに変数をつくることを検討しましょう。
モデル、というと大げさですが、ある閾値を超えたらアラートを受信する、というようなことは、サーバ監視などで日常的にやっていることだなあ、と感じました。
17. レコメンドエンジン
続いて、機械学習の応用の中でも知名度抜群のレコメンドエンジン、協調フィルタリングのアルゴリズムについて説明していました。
例えば、映画を☆の数で評価するようなサイトで、サイト訪問者に好きそうな映画をレコメンドすることを考えます。地道に実行しようとすると、映画のジャンル「恋愛」「アクション」を表す変数を作成し、ひとり一人線形回帰を実施して、その人が特定のジャンルの映画につける☆の数を予想することは可能です。とはいえ、ひとりひとり学習しなければいけないし、「ジャンル」という変数をつくるのも難しいです。というかめんどくさい。
協調フィルタリングアルゴリズムを適用すれば、「ジャンル」を表すような変数を算出することができます。同じ嗜好の人は同じジャンルの映画が好きなはず。ですから、個人の嗜好がわかれば、その映画がどのようなジャンルのものなのか得点をつけることができます(恋愛度80% アクション度20%、など)。逆に、その映画がどのジャンルなのかわかれば、その顧客の好きなジャンルを計算することができます。このようにジャンル→嗜好→ジャンル→嗜好→ジャンルと計算を繰り返し実行することにより、ベストな「ジャンル」をつけることができます。これが大まかな協調フィルタリングの計算の流れです。計算を繰り返すなのが面倒な場合は、嗜好とジャンルが最適なものになるように一緒に計算する手法もあります。
この手法を適用すると、映画をジャンルのベクトルに変換することができ、似た映画を見つけることもできるようになります。また、この手法は発信したレビューをもとに嗜好を予測しているのですが、なにもレビューを書いてない人は情報がないので、なにも勧められません。このような場合は、平均的な人と仮定してレコメンドしたらよいでしょう。
レコメンドエンジンも協調フィルタリングも、実は実装方法はさまざまで、このアルゴリズムも一例にすぎません。が、面白いですね。自動で推薦することはWebサイトの基本機能になりつつありますね。
18. 大規模機械学習
ここ5年でデータが爆発的に増えたため、機械学習の精度はどんどんよくなってきています。反面、別の難しさも見えてきました。例えば最急降下法です。この手法はデータ数だけ計算を繰り返すため、データ量が増えると実行時間が非常に長くなってしまいます。
データは多い方がいい。とはいうものの、データが多いと計算が大変。ではどれくらい多ければ問題ないレベルなのか。これを確かめるためのツールが学習曲線です。学習曲線は、横軸に学習データ数、縦軸に学習モデルのパフォーマンスを描いたグラフです。これで、学習データをふやしてもさほどパフォーマンスがあがらない、という箇所が見えるようになります。こうなった場合は学習データを増やすことは無駄で、パフォーマンスをよくするには変数を増やしたり、モデルを複雑にしたり、と対策を実施する必要があります。
さて、最急降下法はデータ数が多いと計算コストが高くなります。なぜなら、1ステップごとにデータ数分だけ計算をするからです。この問題を解決する案のひとつとして、Stochastic gradient descentというものがあります。これは以下の手順で実行します。
- データセットをランダムにシャッフルする。
- 各パラメータを少しずつ調整する操作をデータ数分だけ繰り返す
1回のイテレーションで全データ・全パラメータを学習するBatch gradient descentに対してStochastic gradient descentはパラメータごとに学習データを1個しか利用しないので、計算はすごくはやい!です。ただ、Batch gradient descentと違って、Stochastic はきちんと尤度が下がっていくとは限らないし、最小に収束とも限りません。ですが、おおよそ最小に収束するので、問題ありません。さらに、もう少し応用したものとして、mini batch gradient descentというものあります。 1個のイテレーションで有限個の学習データを使う方法です。BatchとStochasticのちょうど中間、といったところでしょうか。
Stochastic gradientでは、例えば1000イテレーションごとにcost の平均を計算し、収束しているか確認する、といったこともした方がよいでしょう。また、αのとりかたによっては収束しないので、ちょっとずつαを小さくするのがおすすめです。
大規模機械学習としては、オンライン学習というものもあります。これはデータを獲得した場合、その都度学習しモデルを進化させていく手法です。学習データをためといて一気に処理をする、といった形式ではないので、例えば、証拠など学習データの変数が増えた場合なども、モデルを一から計算しなおすことなく、変数を追加することも可能です。
あと、大規模機械学習といえば、MapReduceなどの学習の並列化も常に検討する必要があります。基本的に計算の手続きの全部、あるいは一部をsumのような可換の処理の形で表現できれば、その部分を並列処理することにより学習時間を抑えることができます。
19 . 応用例:Photo OCR
最後に、今まで学んだ様々なアルゴリズムを組み合わせて、アプリケーションを作成する例を紹介していました。Photo OCR、写真の文字を認識するアプリケーションです。

一見難しい問題も、いくつかのステップに分解すれば、既知のアルゴリズムの組み合わせになります。Photo OCRは以下の3ステップに分けていました。
- テキスト検出
- 文字分割
- 文字分類
それではひとつひとつのステップを見ていきましょう。
まずはテキスト検出です。
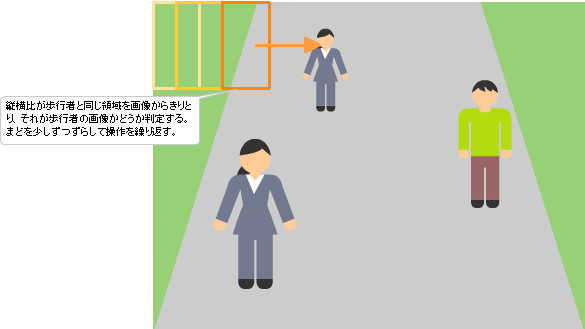
その前に、写真から特定のものを検出する例として、歩行者を検出する処理を考えましょう。歩行者の場合、大きさはいろいろですが縦横比がほぼ一定という特徴があります。
これより、まず、82x36の正解歩行者画像と不正解画像を集めて教師あり学習を実施し、歩行者を判別できるようにします。次に、検出したい画像から縦横比82x36のエリアをはしから順に切り取り、それが歩行者画像かどうか判別していきます。これを Sliding window detection といいます。
テキスト検出ももほぼ同じです。まず、テキストを含む画像と含まない不正解画像で、教師あり学習を実施し、テキストが含まれるか判別できるようにします。その後、Sliding window detectionを実行し、テキストがありそうな部分とない部分にわけます。最後に、可能性があるところとその周辺は「正解」にし、横長のエリアを「テキストがある」とします。
次に文字に分割します。
これもまずは教師あり学習を実行し、分割できるものできないものに分けます。その後、検出された各テキスト領域にSliding Window detectionを実施し、分けられるならば、真ん中に文字の境界線を引いていきます。
最後に文字の分類です。これはロジスティック回帰やニューラルネットワークなど分類する教師あり学習そのものですね。
すこし手間がかかりますが、アルゴリズムをいろいろ組み合わせれば、高度なアプリケーションが生成できます。面白いですね。
さて、Photo OCRでは3回、教師あり学習を実施しましたが、学習データを収集するのが大変です。このような場合は、ある程度人工的に学習データを生成することも考慮しなければいけません。Photo OCRを実施するならば、フォントをいろいろ変えてテキスト画像を生成したり、そのデータを少し歪ませたりして学習データを生成したらよいでしょう。あるいは、音声認識などで音声の学習データは、普通に録音した音声だけでなく、携帯電話や周囲に雑音がある箇所でも音声も利用します。そのようにさまざまな場所で採取した音声を加工して学習データにします。音声や画像を加工して学習データを生成する場合、ランダムにノイズを入れるのはあまり効果がないので注意が必要です。
いずれにしろ、データの取得は機械学習での大きな課題ですが、コストもかかります。「もう少しデータを収集しよう」と実行する前に、いまいちど以下の点を確認しましょう。
- このモデルの精度が低いのは、本当にlow biasだからなのか?
そうでない場合、データを増やしても精度は良くならない。 - 10倍のデータを手に入れたとして、どのくらいパフォーマンスよくなるの?以下のようなことが試せないか?
- 人工的にデータを増やす
- 自分自身でデータの収集とラベル付けを実施する
- インターネットなどにあるオープンなデータを利用する。
最後に。Photo OCRのようにいくつかのステップが組み合わさっているような機械学習のパフォーマンスを改善する場合、重要なのは「どのステップが本当に問題なのか」見極めることです。見極めるための手法「ceiling analysis」を紹介していました。
アプリケーション全体のパフォーマンスを測定します。次に最初のステップテキスト検出を人間の眼で実施し正答率100%にし、全体の正確性がどう変わるかみています。同じように、第2ステップ、第3ステップ、、と人間の眼で実施後、全体の精度が変化するか確認します。
例えば、テキスト検出の正答率を100%にした場合、全体のパフォーマンスが90%にまであがり、文字分割まで100%にした場合の全体のパフォーマンスが91%だったとします。このような場合は、文字分割や文字分類よりテキスト検出のステップを改良すると、全体のパフォーマンスがぐっとあがるでしょう。
Photo OCR。日本語みたいに横書きも縦書きもあり文字の種類も多い場合は難易度あがりそうですね。
講義を振り返って
というわけで全講義終了! 7月には終わっていたのですが、8月の半ばころに、修了証明書が送られてきました。わーい。

ほめられるために勉強しているわけではないのですが、ほめられるとうれしいです。
さて、Andrew先生の講義、はじめて機械学習を学ぶ人のための講座として本当におすすめです。
というのは、数式がでてくる前に、何がしたくて、どういう風に考えてこういう数式になったか、ということをグラフや例で非常に丁寧に説明しているからです。本ではない講義形式だからこその表現力も感じました。英語もそれほど早くなくわかりやすかったし、多少聞き取れなくても資料の英語の文字を追えば意図はわかります。もちろん講義でつかった資料もすべて公開されています。
とはいうものの、1週間ごとのプログラミング課題の提出、結構くじけそうなときもありました。なんとか続けられたのも、ブログを書いていたから!みなさん、ありがとうございました。
